

O futuro do aprendizado profundo pode ser dividido nesses 3 paradigmas de aprendizado

O futuro do aprendizado profundo pode ser dividido nesses 3 paradigmas de aprendizado
Aprendizado híbrido, composto e reduzido
Site original:
O aprendizado profundo é um campo vasto, centrado em um algoritmo cuja forma é determinada por milhões ou mesmo bilhões de variáveis e está sendo constantemente alterada – a rede neural. Parece que a cada dois dias uma quantidade esmagadora de novos métodos e técnicas estão sendo propostas.
Em geral, no entanto, o aprendizado profundo na era moderna pode ser dividido em três paradigmas fundamentais de aprendizado. Dentro de cada um está uma abordagem e uma crença em relação ao aprendizado que oferece potencial e interesse significativos para aumentar o poder e o escopo atuais do aprendizado profundo.
Aprendizagem híbrida — como os métodos modernos de aprendizado profundo podem cruzar as fronteiras entre aprendizado supervisionado e não supervisionado para acomodar uma grande quantidade de dados não rotulados não utilizados?
Aprendizagem composta — como diferentes modelos ou componentes podem ser conectados em métodos criativos para produzir um modelo composto maior que a soma de suas partes?
Aprendizado reduzido — como o tamanho e o fluxo de informações dos modelos podem ser reduzidos, tanto para fins de desempenho quanto de implantação, mantendo o mesmo ou maior poder preditivo?
O futuro do aprendizado profundo está nesses três paradigmas de aprendizado, cada um deles fortemente interconectado.
Aprendizagem Híbrida
Este paradigma procura cruzar as fronteiras entre aprendizagem supervisionada e não supervisionada. É frequentemente usado no contexto de negócios devido à falta e ao alto custo dos dados rotulados. Em essência, a aprendizagem híbrida é uma resposta à pergunta:
Como posso usar métodos supervisionados para resolver/em conjunto com problemas não supervisionados?
Por um lado, o aprendizado semi-supervisionado está ganhando terreno na comunidade de aprendizado de máquina por ser capaz de funcionar excepcionalmente bem em problemas supervisionados com poucos dados rotulados. Por exemplo, um GAN (Generative Adversarial Network) semi-supervisionado bem projetado alcançou mais de 90% de precisão no conjunto de dados MNIST depois de ver apenas 25 exemplos de treinamento.
O aprendizado semi-supervisionado é projetado para conjuntos de dados em que há muitos dados não supervisionados, mas pequenas quantidades de dados supervisionados. Enquanto tradicionalmente um modelo de aprendizado supervisionado seria treinado em uma parte dos dados e um modelo não supervisionado na outra, um modelo semissupervisionado pode combinar dados rotulados com insights extraídos de dados não rotulados.
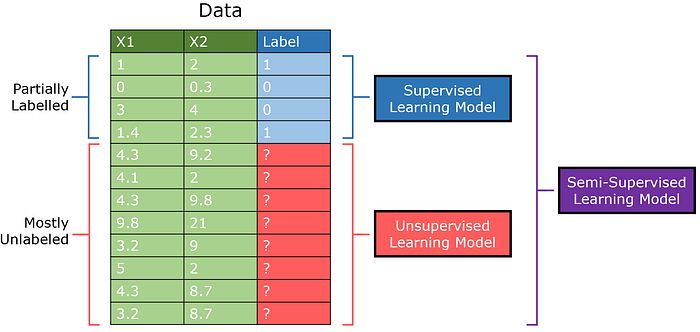
O GAN semi-supervisionado (abreviado como SGAN), é uma adaptação do padrão Modelo de rede adversária generativa. O discriminador tanto emite 0/1 para indicar se uma imagem é gerada ou não, mas também emite a classe do item (aprendizagem de múltiplas saídas).
Isso tem como premissa a ideia de que através do discriminador aprendendo a diferenciar entre imagens reais e geradas, ele é capaz de aprender suas estruturas sem rótulos concretos. Com reforço adicional de uma pequena quantidade de dados rotulados, os modelos semissupervisionados podem alcançar desempenhos superiores com quantidades mínimas de dados supervisionados.
Você pode ler mais sobre SGANs e aprendizado semi-supervisionado aqui.
As GANs também estão envolvidas em outra área de aprendizagem híbrida — auto-supervisionado aprendizagem, em que problemas não supervisionados são explicitamente enquadrados como supervisionados. As GANs criam artificialmente dados supervisionados através da introdução de um gerador; rótulos são criados para identificar imagens reais/geradas. A partir de uma premissa não supervisionada, foi criada uma tarefa supervisionada.
Alternativamente, considere o uso de modelos de codificador-decodificador para compressão. Em sua forma mais simples, são redes neurais com uma pequena quantidade de nós no meio para representar algum tipo de gargalo, forma compactada. As duas seções de cada lado são o codificador e o decodificador.
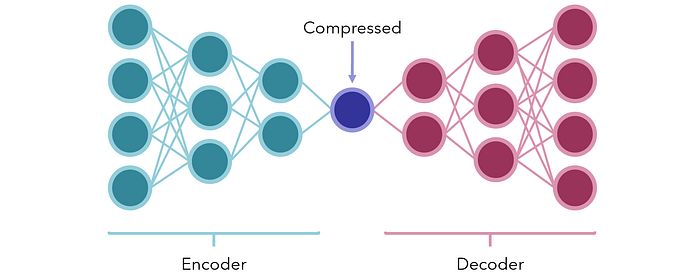
A rede é treinada para produzir o mesmo saída como a entrada vetorial (uma tarefa supervisionada criada artificialmente a partir de dados não supervisionados). Como há um gargalo deliberadamente colocado no meio, a rede não pode transmitir passivamente as informações; em vez disso, deve encontrar as melhores maneiras de preservar o conteúdo da entrada em uma unidade pequena, de modo que possa ser razoavelmente decodificada novamente pelo decodificador.
Depois de treinados, o codificador e o decodificador são desmontados e podem ser usados nas extremidades de recepção de dados compactados ou codificados para transmitir informações de forma extremamente pequena com pouca ou nenhuma perda de dados. Eles também podem ser usados para reduzir a dimensionalidade dos dados.
Como outro exemplo, considere uma grande coleção de textos (talvez comentários de uma plataforma digital). Através de algum agrupamento ou aprendizagem múltipla método, podemos gerar rótulos de cluster para coleções de textos e tratá-los como rótulos (desde que o agrupamento seja bem feito).
Depois que cada cluster é interpretado (por exemplo, cluster A representa comentários reclamando sobre um produto, cluster B representa feedback positivo, etc.) uma arquitetura de NLP profunda como BERT pode então ser usado para classificar novos textos nesses grupos, todos com dados completamente não rotulados e envolvimento humano mínimo.
Esta é mais uma vez uma aplicação fascinante de converter tarefas não supervisionadas em supervisionadas. Em uma era em que a grande maioria de todos os dados são dados não supervisionados, há um enorme valor e potencial na construção de pontes criativas para cruzar as fronteiras entre aprendizado supervisionado e não supervisionado com aprendizado híbrido.
Aprendizado Composto
A aprendizagem composta procura utilizar o conhecimento não de um modelo, mas de vários. É a crença de que, por meio de combinações únicas ou injeções de informações – tanto estáticas quanto dinâmicas – o aprendizado profundo pode se aprofundar continuamente na compreensão e no desempenho do que um único modelo.
O aprendizado de transferência é um exemplo óbvio de aprendizado composto e tem como premissa a ideia de que os pesos de um modelo podem ser emprestados de um modelo pré-treinado em uma tarefa semelhante e depois ajustados em uma tarefa específica. Modelos pré-treinados como Começo ou VGG-16 são construídos com arquiteturas e pesos projetados para distinguir entre várias classes diferentes de imagens.
Se eu fosse treinar uma rede neural para reconhecer animais (gatos, cachorros, etc.), não treinaria uma rede neural convolucional do zero porque levaria muito tempo para obter bons resultados. Em vez disso, eu pegaria um modelo pré-treinado como Inception, que já armazenou o básico do reconhecimento de imagem, e treinaria por algumas épocas adicionais no conjunto de dados.
Da mesma forma, as incorporações de palavras em redes neurais de PNL, que mapeiam palavras fisicamente mais próximas de outras palavras em um espaço de incorporação, dependendo de seus relacionamentos (por exemplo, 'maçã' e 'laranja' têm distâncias menores que 'maçã' e 'caminhão'). Embeddings pré-treinados como o GloVe podem ser colocados em redes neurais para começar do que já é um mapeamento eficaz de palavras para entidades numéricas e significativas.
Menos obviamente, a competição também pode estimular o crescimento do conhecimento. Por um lado, as Redes Adversariais Generativas emprestam do paradigma de aprendizado composto, colocando fundamentalmente duas redes neurais uma contra a outra. O objetivo do gerador é enganar o discriminador, e o objetivo do discriminador não é ser enganado.
A competição entre modelos será chamada de 'aprendizagem adversarial', não devendo ser confundida com outro tipo de aprendizagem adversarial que se refere ao design de entradas maliciosas e exploração de limites de decisão fracos em modelos.
A aprendizagem adversarial pode estimular modelos, geralmente de diferentes tipos, nos quais o desempenho de um modelo pode ser representado em relação ao desempenho de outros. Ainda há muita pesquisa a ser feita no campo da aprendizagem adversarial, sendo a rede adversarial generativa a única criação proeminente do subcampo.
O aprendizado competitivo, por outro lado, é semelhante ao aprendizado adversário, mas é realizado na escala nó por nó: os nós competem pelo direito de responder a um subconjunto dos dados de entrada. A aprendizagem competitiva é implementada em uma 'camada competitiva', na qual um conjunto de neurônios são todos iguais, exceto por alguns pesos distribuídos aleatoriamente.
O vetor de peso de cada neurônio é comparado ao vetor de entrada e o neurônio com a maior similaridade, o neurônio 'vencedor leva tudo', é ativado (saída = 1). Os outros estão 'desativados' (saída = 0). Esta técnica não supervisionada é um componente central da mapas auto-organizados e descoberta de recursos.
Outro exemplo interessante de aprendizagem composta é em pesquisa de arquitetura neural. Em termos simplificados, uma rede neural (geralmente recorrente) em um ambiente de aprendizado por reforço aprende a gerar a melhor rede neural para um conjunto de dados — o algoritmo encontra a melhor arquitetura para você! Você pode ler mais sobre a teoria aqui e implementação em Python aqui.
Os métodos ensemble também são essenciais no aprendizado composto. Os métodos de ensemble profundos têm se mostrado muito eficaz, e o empilhamento de modelos de ponta a ponta, como codificadores e decodificadores, aumentou em popularidade.
Grande parte do aprendizado composto é descobrir maneiras únicas de construir conexões entre diferentes modelos. Parte-se da ideia de que,
Um único modelo, mesmo um muito grande, tem um desempenho pior do que vários modelos/componentes pequenos, cada um delegado para se especializar em parte da tarefa.
Por exemplo, considere a tarefa de construir um chatbot para um restaurante.

Podemos segmentá-lo em três partes separadas: brincadeiras/bate-papo, recuperação de informações e uma ação, e projetar um modelo para se especializar em cada uma. Alternativamente, podemos delegar um modelo singular para realizar todas as três tarefas.
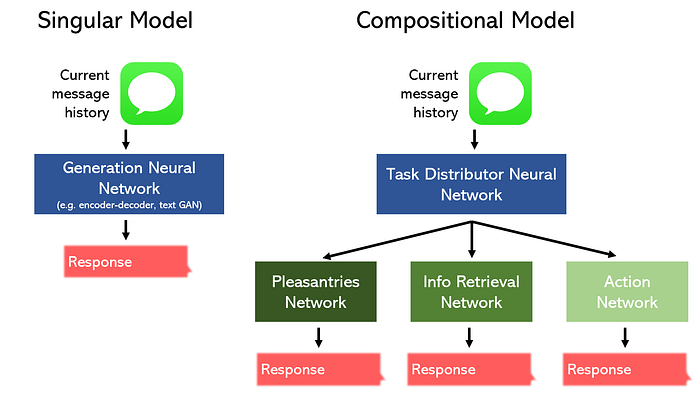
Não deve ser surpresa que o modelo composicional possa ter um desempenho melhor enquanto ocupa menos espaço. Além disso, esses tipos de topologias não lineares podem ser facilmente construídas com ferramentas como API funcional do Keras.
Para processar uma crescente diversidade de tipos de dados, como vídeos e dados tridimensionais, os pesquisadores devem construir modelos de composição criativos
Leia mais sobre aprendizagem composicional e o futuro aqui.
Aprendizado Reduzido
O tamanho dos modelos, particularmente em PNL – o epicentro da empolgação agitada na pesquisa de aprendizado profundo – está crescendo, por muito. O modelo GPT-3 mais recente tem 175 bilhão parâmetros. Comparando-o com BERT é como comparar Júpiter a um mosquito (bem, não literalmente). O futuro do aprendizado profundo é maior?
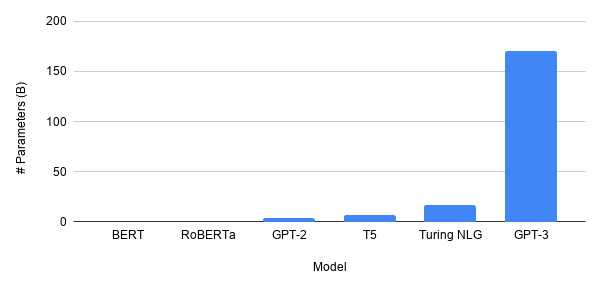
Muito provavelmente, não. O GPT-3 é muito poderoso, reconhecidamente, mas mostrou repetidamente no passado que 'ciências bem-sucedidas' são aquelas que têm o maior impacto na humanidade. Sempre que a academia se afasta demais da realidade, geralmente desaparece na obscuridade. Este foi o caso quando as redes neurais foram esquecidas no final dos anos 1900 por um breve período de tempo porque havia tão poucos dados disponíveis que a ideia, por mais engenhosa que fosse, era inútil.
O GPT-3 é outro modelo de linguagem e pode escrever textos convincentes. Onde estão suas aplicações? Sim, poderia gerar, por exemplo, respostas a uma consulta. Existem, no entanto, maneiras mais eficientes de fazer isso (por exemplo, percorrer um gráfico de conhecimento e usar um modelo menor como o BERT para gerar uma resposta).
Simplesmente não parece ser o caso que o tamanho massivo do GPT-3, para não mencionar um modelo maior, seja viável ou necessário, dado um secando de poder computacional.
“A Lei de Moore está meio que perdendo força.”
- Satya Nadella, CEO da Microsoft
Em vez disso, estamos caminhando para um mundo integrado à IA, onde uma geladeira inteligente pode fazer pedidos automáticos de mantimentos e os drones podem navegar por cidades inteiras por conta própria. Métodos poderosos de aprendizado de máquina devem poder ser baixados em PCs, telefones celulares e pequenos chips.
Isso exige IA leve: tornando as redes neurais menores e mantendo o desempenho.
Acontece que, direta ou indiretamente, quase tudo na pesquisa de deep learning tem a ver com a redução da quantidade necessária de parâmetros, o que anda de mãos dadas com a melhoria da generalização e, portanto, do desempenho. Por exemplo, a introdução de camadas convolucionais reduziu drasticamente o número de parâmetros necessários para as redes neurais processarem imagens. As camadas recorrentes incorporam a ideia de tempo usando os mesmos pesos, permitindo que as redes neurais processem sequências melhor e com menos parâmetros.
A incorporação de camadas mapeia explicitamente as entidades para valores numéricos com significados físicos, de modo que a carga não seja colocada em parâmetros adicionais. Em uma interpretação, Cair fora camadas bloqueiam explicitamente os parâmetros de operar em certas partes de uma entrada. Regularização L1/L2 garante que uma rede utilize todos os seus parâmetros, certificando-se de que nenhum deles cresça muito e que cada um maximize seu valor de informação.
Com a criação de camadas especializadas, as redes exigem cada vez menos parâmetros para dados mais complexos e maiores. Outros métodos mais recentes buscam explicitamente comprimir a rede.
Poda de rede neural procura remover sinapses e neurônios que não agregam valor à saída de uma rede. Por meio da poda, as redes podem manter seu desempenho enquanto removem quase tudo de si mesmas.
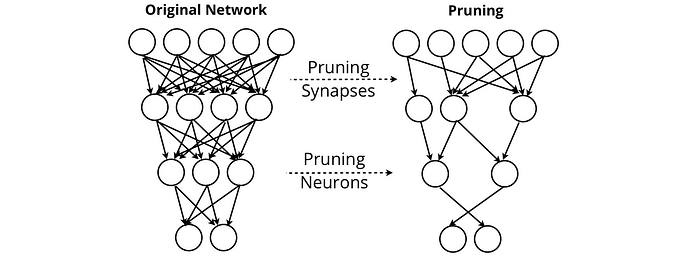
Outros métodos como Destilação do Conhecimento do Paciente encontre métodos para compactar grandes modelos de linguagem em formulários que podem ser baixados, por exemplo, nos telefones dos usuários. Esta foi uma consideração necessária para a Sistema de tradução automática neural do Google (GNMT), que alimenta o Google Translate, que precisava criar um serviço de tradução de alto desempenho que pudesse ser acessado offline.
Em essência, o aprendizado reduzido gira em torno do design centrado na implantação. É por isso que a maioria das pesquisas para aprendizagem reduzida vem do departamento de pesquisa das empresas. Um aspecto do design centrado na implantação não é seguir cegamente as métricas de desempenho em conjuntos de dados, mas focar em possíveis problemas quando um modelo é implantado.
Por exemplo, já mencionado entradas adversárias são entradas maliciosas projetadas para enganar uma rede. Tinta spray ou adesivos em placas podem enganar os carros autônomos para acelerar bem acima do limite de velocidade. Parte do aprendizado reduzido responsável não é apenas tornar os modelos leves o suficiente para uso, mas garantir que eles possam acomodar casos de canto não representados em conjuntos de dados.
O aprendizado reduzido talvez esteja recebendo menos atenção da pesquisa em aprendizado profundo, porque “conseguimos alcançar um bom desempenho com um tamanho de arquitetura viável” não é tão atraente quanto “atingimos um desempenho de última geração com uma arquitetura que consiste de kajillions de parâmetros”.
Inevitavelmente, quando a busca exagerada de uma fração maior de uma porcentagem desaparecer, como mostra a história da inovação, o aprendizado reduzido – que na verdade é apenas o aprendizado prático – receberá mais da atenção que merece.
Resumo
O aprendizado híbrido procura cruzar os limites do aprendizado supervisionado e não supervisionado. Métodos como aprendizado semi-supervisionado e auto-supervisionado são capazes de extrair insights valiosos de dados não rotulados, algo incrivelmente valioso à medida que a quantidade de dados não supervisionados cresce exponencialmente.
À medida que as tarefas se tornam mais complexas, o aprendizado composto desconstrói uma tarefa em vários componentes mais simples. Quando esses componentes trabalham juntos – ou uns contra os outros – o resultado é um modelo mais poderoso.
O aprendizado reduzido não recebeu muita atenção, pois o aprendizado profundo passa por uma fase de hype, mas em breve a praticidade e o design centrado na implantação surgirão.
Obrigado por ler!
Declaração: apenas para intercâmbio acadêmico. Os direitos autorais deste artigo pertencem ao autor original. Se houver algo errado, entre em contato para excluir.